在Linux服务器管理中,实时监控服务器状态是确保系统稳定运行的关键环节,通过命令行工具,管理员可以高效获取CPU、内存、磁盘、网络等核心资源的使用情况,及时发现潜在问题并采取优化措施,本文将详细介绍Linux服务器状态查看的常用命令及其应用场景,帮助管理员全面掌握系统监控技巧。

CPU状态监控
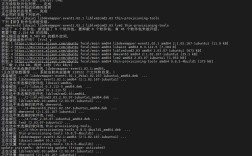
CPU是服务器的核心组件,其负载情况直接影响系统性能,使用top命令可以实时查看各进程的CPU占用率、内存使用量等信息,默认按CPU使用率降序排列,按P键可切换至CPU排序,按M键则按内存排序,若需查看CPU负载历史,uptime命令可显示1分钟、5分钟和15分钟的平均负载,数值超过CPU核心数时表示系统过载,对于更详细的CPU分析,mpstat命令来自sysstat包,可按核心统计CPU使用率、空闲率、系统调用次数等,例如mpstat -P ALL 1每秒刷新各核心数据。
内存使用分析
内存不足会导致系统性能下降甚至崩溃。free命令是查看内存使用情况的利器,free -h以人类可读格式显示总内存、已用、空闲、缓冲区及缓存信息。buff/cache列表示内核缓冲区和页缓存,可通过释放这部分内存临时缓解内存压力,若需分析进程内存占用,ps aux --sort=-%mem可按内存使用率排序显示进程,结合grep过滤特定进程,对于虚拟内存(Swap)的使用,swapon --show可查看Swap分区信息,当Swap使用率过高时,需检查内存泄漏或增加物理内存。
磁盘与文件系统监控
磁盘空间不足可能引发服务异常,而磁盘I/O瓶颈会影响读写性能。df -h命令以GB/MB为单位显示各分区的使用率、挂载点及剩余空间,重点关注Use%列接近100%的分区,若需定位大文件,du -sh /*可统计根目录下各子目录的大小,find / -type f -size +100M可查找超过100MB的文件,对于磁盘I/O性能,iostat -xz 1命令显示磁盘的读写速率、I/O请求队列长度及等待时间,%util列超过70%表示磁盘存在I/O瓶颈。
网络状态检查
网络问题可能导致服务不可用,需关注网络连接、带宽及端口状态。netstat -tuln显示当前监听的TCP/UDP端口及协议类型,结合grep可过滤特定端口,若需查看活跃的网络连接,ss -tulnp比netstat更高效,能显示进程PID及名称,带宽监控方面,iftop和nethogs是常用工具,前者按实时流量排序显示IP连接,后者按进程统计网络带宽占用,对于网络连通性,ping测试目标主机可达性,traceroute可追踪数据包路径,定位网络延迟或丢包节点。

系统日志与进程管理
系统日志记录了关键事件,是排查问题的重要依据。journalctl -xe查看系统日志,-f参数实时跟踪日志更新,grep "error"可过滤错误信息,进程管理方面,ps aux显示所有进程的详细信息,kill -9 PID强制终止进程,systemctl status service_name检查系统服务状态,对于资源占用异常的进程,nice和renice命令可调整进程优先级,避免影响关键服务。
综合监控工具
除基础命令外,htop以彩色界面提供更直观的进程监控,支持鼠标操作和树形结构显示。nmon是一款性能分析工具,可同时监控CPU、内存、磁盘、网络等资源,并生成报告文件,对于长期监控,zabbix和prometheus等开源工具支持数据采集、可视化及告警,适合企业级服务器集群管理。
相关问答FAQs
Q1: 如何判断Linux服务器是否过载?
A1: 可通过以下指标综合判断:1)uptime命令显示的15分钟平均负载持续超过CPU核心数;2)top或htop中CPU系统态(%sys)和等待态(%wa)占比过高;3)free命令中Swap使用率超过20%;4)磁盘iostat的%util持续高于70%,若出现多项异常,需优化进程或升级硬件。
Q2: 如何定位导致高CPU占用的进程?
A2: 可按以下步骤操作:1)运行top -p 1,按P键按CPU排序,查看占用率最高的进程PID;2)使用ps -p PID -o pid,ppid,cmd,pcpu,pmem获取进程详细信息;3)若为可疑进程,通过kill PID终止或strace -p PID跟踪系统调用;4)对于持续异常的进程,检查日志或使用gdb调试分析原因。