Java Web服务器监控是确保应用程序稳定运行、快速响应问题以及优化性能的关键环节,通过实时监控服务器的各项指标,运维人员可以及时发现潜在风险,避免服务中断,同时为系统扩容和性能调优提供数据支持,以下是Java Web服务器监控的核心内容,涵盖监控指标、常用工具及实践方法。

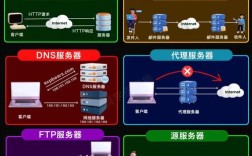
监控指标可分为系统级、应用级和业务级三大类,系统级指标主要关注服务器的硬件和操作系统资源,包括CPU使用率(需区分用户态、内核态和空闲率)、内存占用(堆内存、非堆内存及交换空间使用情况)、磁盘I/O(读写速率、I/O等待时间)和网络流量(带宽利用率、连接数),CPU持续高于80%可能意味着存在性能瓶颈,而内存泄漏会导致堆内存持续增长直至OOM崩溃,应用级指标聚焦于Java应用本身,JVM监控是核心,需关注GC频率与耗时(如Young GC和Full GC的次数和时间)、线程状态(活跃线程数、死锁线程)、类加载情况(加载类数量、卸载类数量)以及JVM内存池(Eden、Survivor、Old区的使用率),Web容器指标如Tomcat的线程池(最大线程数、当前活跃线程数)、请求处理时间(平均响应时间、最大响应时间)、错误率(5xx、4xx占比)和吞吐量(QPS、TPS)也需重点监控,业务级指标则根据具体应用场景设定,如订单系统中的下单成功率、用户登录失败率等,这些指标直接反映业务健康度。
实现监控可通过多种工具组合,开源工具中,Prometheus + Grafana是主流方案,通过Prometheus采集JMX指标(使用JMX Exporter),结合Grafana可视化展示,支持告警规则配置;Zabbix适合基础设施监控,可通过Agent采集服务器硬件指标,并集成JMX插件监控应用;ELK(Elasticsearch、Logstash、Kibana)则擅长日志分析,通过过滤和聚合错误日志、慢查询日志,定位应用问题,商业工具如Dynatrace、New Relic提供全栈监控能力,能自动发现性能瓶颈,并生成调用链分析,适合对监控深度要求高的场景,JDK自带的jstat、jstack、jmap等命令适合临时排查问题,如jstat -gcutil pid可实时查看GC情况,jstack pid可导出线程堆栈检测死锁。
监控实践需遵循“全面覆盖、重点突出、实时告警”原则,建立监控基线,通过系统正常运行时的指标数据,定义各阈值(如CPU使用率基线70%,超过则告警);设置多级告警机制,通过邮件、短信、企业微信等方式通知,区分紧急级别(如服务器宕机需立即处理,而内存缓慢增长可定期排查);定期分析监控数据,结合业务高峰期调整资源分配,例如大促前扩容线程池,避免请求堆积。
相关问答FAQs

-
问:如何区分JVM堆内存溢出和非堆内存溢出?
答:堆内存溢出(OOM)通常表现为“java.lang.OutOfMemoryError: Java heap space”,可通过内存快照(jmap dump)分析对象是否无法被回收;非堆内存溢出可能由元空间(Metaspace,如加载过多类)、线程栈(如线程数过多导致栈内存不足)或直接内存(NIO使用过多)引起,错误信息会明确提示具体区域,如“Metaspace”或“Native memory”,需通过jstat -gccapacity查看各区域使用情况,并结合jstack分析线程状态。 -
问:监控到Tomcat线程池队列积压,如何快速定位原因?
答:通过Tomcat Manager或JMX查看当前活跃线程数、队列长度及请求处理时间,若活跃线程数接近最大线程数且处理时间长,可能是后端服务(如数据库、RPC调用)慢导致;分析应用日志,查找慢查询SQL或异常堆栈;使用Arthas等工具在线诊断方法耗时,定位具体代码瓶颈,若确认是资源不足,可临时扩容线程池,并优化后端服务性能或增加缓存。