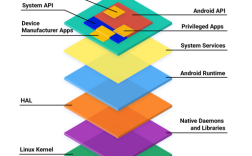
构建和维护高性能Linux服务器是现代IT基础设施的核心任务,涉及硬件选型、系统优化、资源调度、安全加固及监控调优等多个维度,其目标是通过技术手段实现高并发处理、低延迟响应、高可用性及弹性扩展能力,以满足云计算、大数据、人工智能等场景对算力的严苛需求。
在硬件层面,高性能Linux服务器的搭建需首先明确应用负载特征,对于CPU密集型任务(如科学计算、数据库事务),应优先选择多路高主频处理器,如Intel Xeon Scalable系列或AMD EPYC系列,其支持的大容量缓存和超线程技术能显著提升并行处理能力;对于I/O密集型场景(如分布式存储、视频流处理),则需重点配置NVMe SSD阵列,利用PCIe 4.0/5.0接口的高带宽特性(单路可达32GB/s),并结合RAID控制器实现数据冗余与性能均衡,内存方面,采用ECC(Error-Correcting Code)内存可降低软错误风险,而支持RDIMM/LRDIMM的大容量内存扩展(可至数TB)则为内存数据库、虚拟化平台等应用提供基础,网络配置上,采用25GbE/100GbE高速网卡,结合SR-IOV技术实现虚拟机直通,减少网络延迟;同时部署TOE(TCP Offload Engine)网卡卸载TCP/IP协议栈开销,进一步提升数据传输效率。
操作系统优化是发挥硬件潜力的关键,Linux内核参数需根据负载类型调整:对于高并发连接场景,通过net.core.somaxconn增大监听队列长度(如65535),net.ipv4.tcp_max_syn_backlog优化半连接数上限;针对内存敏感型应用,通过vm.swappiness降低swap交换倾向(如10),并启用transparent_hugepage(需谨慎测试)减少内存碎片,文件系统选择上,XFS适用于大文件高并发场景(如视频存储),其异步特性和在线扩容能力优势显著;而ext4则在中小文件场景下表现稳定,支持快照功能便于数据备份,进程调度方面,实时内核(PREEMPT_RT)可确保关键任务毫秒级响应,适用于工业控制、高频交易等领域;常规场景则可通过cpuset、cpuacct等cgroup子系统实现CPU资源隔离,避免业务间相互干扰。
资源管理与调度是提升服务器整体效能的核心,容器化技术(如Docker+Kubernetes)通过轻量级隔离和资源限制,实现应用密度与稳定性的平衡;而虚拟化平台(KVM+OpenStack)则通过硬件辅助虚拟化(Intel VT-x/AMD-V)提升I/O性能,适合多租户混合部署,对于数据库等关键服务,采用连接池(如PgBouncer)减少连接建立开销,通过读写分离、分库分表策略分散负载;缓存层(Redis、Memcached)的引入可显著降低后端数据库压力,需根据数据特征选择淘汰算法(如LRU、LFU),NUMA(Non-Uniform Memory Access)架构优化不可忽视,通过numactl工具将进程绑定至本地NUMA节点,避免跨节点内存访问导致的性能衰减(可提升20%-30%)。
安全与稳定性是高性能服务器运行的基础,系统层面需启用SELinux/AppArmor强制访问控制,最小化系统服务(使用systemd-target隔离),定期更新内核与应用补丁;网络层面通过iptables/nftables实现精细化流量过滤,结合fail2ban防止暴力破解,数据备份采用“本地快照+异地容灾”双重策略,例如使用LVM快照实现分钟级数据备份,通过rsync+ssh定期同步至远程存储,监控体系需覆盖硬件(如ipmiutil监控服务器温度、电压)、系统(如Prometheus+Grafana采集CPU/内存/磁盘I/O指标)及应用层(如SkyWalking追踪事务链路),设置多级告警阈值(如CPU持续80%触发告警),确保故障快速定位与恢复。
为直观展示关键优化方向,以下列举部分参数配置示例:
| 优化方向 | 参数/工具 | 推荐值/场景 | 效果说明 |
|---|---|---|---|
| 网络连接队列 | net.core.somaxconn | 65535 | 提高并发连接处理能力,避免连接丢弃 |
| 内存交换倾向 | vm.swappiness | 10 | 减少swap使用,提升内存响应速度 |
| 文件系统 | XFS(mkfs.xfs) | largeio,swalloc | 优化大文件读写性能,支持在线扩容 |
| CPU资源隔离 | cgroupv2 (cpu.weight) | 业务A: 512,业务B: 256 | 按权重分配CPU资源,防止单业务独占 |
| NUMA绑定 | numactl --cpunodebind | 绑定进程至本地NUMA节点 | 减少跨节点内存访问延迟 |
相关问答FAQs:
Q1:如何判断Linux服务器是否存在CPU瓶颈?
A:可通过top或htop工具观察CPU idle率(持续低于20%可能存在瓶颈)、vmstat查看us(用户态CPU)、sy(内核态CPU)、wa(I/O等待)占比;若us或sy持续过高,需分析进程堆栈(pidstat -t定位高负载线程),考虑优化算法或增加CPU核心数;若wa较高,则需检查磁盘I/O性能。
Q2:在高并发场景下,如何优化Linux网络栈性能?
A:主要从内核参数和硬件卸载两方面入手:① 调整net.ipv4.tcp_rmem和net.ipv4.tcp_wmem增大TCP缓冲区(如4096 65536 16777216);② 启用net.ipv4.tcp_fastopen减少TCP握手延迟;③ 开启网卡ethtool -K eth0 tx tso rx gro on卸载协议栈处理;④ 采用DPDK或RDMA技术绕过内核协议栈,适用于金融、CDN等超低延迟场景。