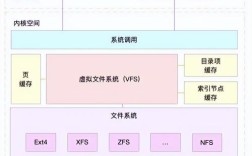
Linux 服务器性能分析是确保系统稳定运行、优化资源利用的关键环节,涉及对 CPU、内存、磁盘 I/O、网络等多个维度的监控与排查,以下从核心指标、分析工具、排查流程及优化建议等方面展开详细说明。

(图片来源网络,侵删)
核心性能指标及分析方法
-
CPU 性能
CPU 是服务器的大脑,主要关注指标包括:- 使用率:用户态(us)、系统态(sy)、等待 I/O(wa)、空闲(id),若
us+sy持续高于 80%,可能存在 CPU 密集型任务;wa过高则说明磁盘 I/O 成为瓶颈。 - 负载均衡:通过
uptime或top查看 1/5/15 分钟平均负载,理想状态下负载值应不超过 CPU 逻辑核心数。 - 上下文切换:频繁的进程切换会导致 CPU 开销增大,可通过
vmstat查看cs(上下文切换次数)和in(中断次数)判断是否异常。
- 使用率:用户态(us)、系统态(sy)、等待 I/O(wa)、空闲(id),若
-
内存性能
内存问题通常表现为系统卡顿或服务 OOM(Out of Memory)。- 使用率:
free -m查看used、free、buff/cache,若available内存持续低于 20%,可能存在内存不足风险。 - Swap 使用:频繁 Swap 交换会导致 I/O 压力增大,可通过
swapon -s监控 Swap 分区使用情况。 - 内存泄漏:通过
pidstat -p <PID> -r定期观察进程 RSS(常驻内存集)是否持续增长。
- 使用率:
-
磁盘 I/O 性能
磁盘 I/O 瓶颈会直接影响文件读写速度和应用响应时间。- IOPS 和吞吐量:使用
iostat -x 1查看await(平均 I/O 等待时间,应低于 10ms)、util(磁盘利用率,超过 70% 需警惕)。 - 文件系统使用率:
df -h监控各分区使用率,建议保留 20% 以上空闲空间。 - 磁盘错误:通过
dmesg | grep -i error检查磁盘硬件错误日志。
- IOPS 和吞吐量:使用
-
网络性能
网络问题可能导致应用延迟或数据传输失败。 (图片来源网络,侵删)
(图片来源网络,侵删)- 带宽使用:
iftop或nload实时监控网络流量,检查是否达到带宽上限。 - 连接数与错误:
netstat -an | awk '/^tcp/ {print $6}'统计 TCP 连接状态(如 TIME_WAIT 过多可能需调整内核参数)。 - 延迟与丢包:
ping和traceroute定期测试目标网络的连通性。
- 带宽使用:
常用性能分析工具
| 工具名 | 功能描述 | 常用命令示例 |
|---|---|---|
top |
实时进程监控,查看 CPU、内存使用及进程排名 | top -i -c(忽略 idle 进程,显示命令行) |
vmstat |
虚拟内存统计,涵盖进程、内存、I/O、CPU 等核心指标 | vmstat 2 5(每 2 秒输出 5 次) |
iostat |
磁盘 I/O 性能分析,支持设备级和文件系统级监控 | iostat -xz 1(显示扩展统计,每秒刷新) |
sar |
系统历史数据收集与分析(需安装 sysstat 包) | sar -u -s 10:00 -e 18:00(统计指定时段 CPU 使用率) |
free |
内存使用情况快速查看 | free -h(以人类可读格式显示) |
netstat |
网络连接、路由表、接口状态统计 | netstat -tuln(显示监听端口) |
pidstat |
进程级别的 CPU、内存、I/O 统计 | pidstat -d -p <PID>(监控指定进程 I/O) |
perf |
Linux 性能剖析工具,支持 CPU 性能事件分析(如缓存命中率、分支预测失败) | perf top(实时热点函数分析) |
性能问题排查流程
- 明确问题现象:应用响应缓慢”“服务器高负载”等,结合业务日志定位具体场景。
- 收集基础数据:通过
top、free、df快速判断 CPU、内存、磁盘是否异常。 - 深度分析瓶颈:若 CPU 高,用
perf record -g生成火焰图分析热点函数;若 I/O 高,通过iostat定位瓶颈磁盘。 - 进程级排查:结合
ps aux --sort=-%cpu找出高 CPU 进程,或strace跟踪系统调用定位问题。 - 内核参数调优:例如调整文件描述符限制(
ulimit)、TCP 连接队列(net.core.somaxconn)、Swap 策略等。
优化建议
- CPU 优化:避免 CPU 密集型任务长时间独占 CPU,可通过
nice调整进程优先级,或使用任务队列分散负载。 - 内存优化:合理配置缓存策略,避免内存泄漏;对大内存服务器可启用
transparent_hugepages提升内存管理效率。 - 磁盘优化:使用 SSD 替换 HDD,对频繁访问的数据启用 RAID 10,调整
noop或deadline调度算法(适用于 SSD)。 - 网络优化:启用 TCP BBR 拥塞控制算法,调整 MTU 减少分片,部署负载均衡分散网络压力。
相关问答 FAQs
Q1:如何判断 Linux 服务器是否存在 CPU 瓶颈?
A1:可通过以下方式综合判断:
- 使用
top或htop观察 CPU 使用率,若us+sy持续高于 80% 且id低于 20%,说明 CPU 负载较高; - 检查
vmstat中的r(运行队列长度)是否持续大于 CPU 逻辑核心数,若大于则存在 CPU 竞争; - 通过
mpstat查看各 CPU 核心使用率是否均衡,若部分核心满载而其他空闲,可能存在进程亲和性问题。
Q2:服务器内存使用率高但 Swap 未使用,是否需要扩容?
A2:不一定需立即扩容,需结合具体场景分析:
- 若
buff/cache占比较高(如超过 50%),说明系统正在利用空闲内存作为文件缓存,属于正常优化行为,可通过echo 3 > /proc/sys/vm/drop_caches清理缓存后观察内存变化; - 若
used内存中大部分被单个进程占用(如数据库、应用服务),且该进程内存持续增长,需排查是否存在内存泄漏; - 若系统频繁触发 OOM(Out of Memory Killer),则需评估业务需求,考虑扩容或优化内存使用效率(如调整 JVM 参数、启用内存池等)。

(图片来源网络,侵删)