第一步:请提供更多信息
在开始诊断之前,请尽可能详细地告诉我以下信息:

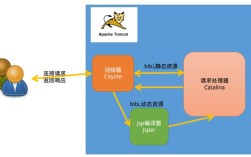
(图片来源网络,侵删)
-
使用的工具/平台是什么?
- 配置管理工具: Ansible, Puppet, Chef, SaltStack?
- 基础设施即代码: Terraform, AWS CloudFormation, Azure ARM Templates?
- CI/CD 工具: Jenkins, GitLab CI, GitHub Actions, CircleCI?
- 脚本: Shell (Bash/PowerShell), Python, Ruby?
- 云平台控制台: AWS Console, Azure Portal, Google Cloud Console 的自动化功能?
-
错误的具体表现是什么?
- 完整的错误信息/日志: 请把完整的错误堆栈、日志、终端输出贴出来,这是最重要的线索!
- 错误发生的阶段: 是在执行
apply、deploy、provision还是run-playbook时? - 失败的任务/步骤: 是哪个具体的任务、资源或步骤失败了?
-
相关的配置文件代码:
如果是代码驱动的自动化(如 Ansible Playbook, Terraform),请贴出相关的代码片段,注意脱敏掉密码、密钥等敏感信息。
 (图片来源网络,侵删)
(图片来源网络,侵删) -
环境和上下文:
- 操作系统: 目标服务器是什么系统?(如 Ubuntu 20.04, CentOS 7, Windows Server 2025)
- 网络环境: 目标服务器是否可以访问?防火墙、VPC、安全组设置是否正确?
- 权限问题: 执行自动化任务的账号是否有足够的权限?(如
sudo权限、云平台的 IAM 角色/权限)
第二步:常见错误类型及排查思路
以下是一些在服务器自动化中最常见的错误类别,你可以看看你的问题属于哪一类。
连接性问题 (Connection Issues)
这是最常见的问题,尤其是在首次配置自动化时。
- 错误表现:
Could not resolve host ...(无法解析主机名)Permission denied (publickey,password).(公钥或密码认证失败)Connection timed out(连接超时)ssh: connect to host ... port 22: Connection refused(端口被拒绝)
- 可能原因:
- 目标服务器 IP/主机名错误或无法访问。
- SSH 服务未启动或配置错误。
- 防火墙阻止了连接(服务器本地防火墙或云平台安全组)。
- SSH 密钥未正确部署到目标服务器的
~/.ssh/authorized_keys文件中。 - 执行自动化任务的用户没有正确的权限。
- 排查思路:
- 手动测试连接: 在执行自动化脚本的主机上,手动尝试
ssh user@target_server_ip,看是否能成功连接。 - 检查网络:
ping目标服务器 IP,看是否通。 - 检查防火墙: 在目标服务器上,检查
ufw(Ubuntu) 或firewalld(CentOS) 的状态,并确保 22 (SSH) 端口是开放的,如果是云服务器,检查对应的安全组/网络ACL规则。 - 检查 SSH 服务: 在目标服务器上运行
systemctl status sshd(或ssh),确保服务是active (running)状态。 - 检查密钥: 确认公钥是否已正确添加到目标服务器的
authorized_keys文件中,并且文件权限正确 (chmod 600 ~/.ssh/authorized_keys)。
- 手动测试连接: 在执行自动化脚本的主机上,手动尝试
权限问题 (Permission Issues)
自动化脚本通常需要 sudo 权限来执行安装软件、修改系统配置等操作。
- 错误表现:
Permission denied(权限被拒绝)... is not in the sudoers file.(用户不在 sudoers 文件中)Failed to set locale, defaulting to C.UTF-8(可能由权限不足导致某些环境变量无法设置)
- 可能原因:
- 执行任务的用户没有
sudo权限。 - Ansible 的
become方法配置错误。 - 脚本尝试写入一个它没有权限写入的目录(如
/usr/local/bin,/etc)。
- 执行任务的用户没有
- 排查思路:
- 手动测试权限: 登录到目标服务器,手动执行
sudo ls /root或sudo apt update,看是否需要输入密码以及是否能成功执行。 - 检查
sudoers文件: 确认执行用户是否在sudoers文件中,或者被包含在某个用户组里(如sudo组)。 - 检查自动化配置:
- Ansible: 检查 Playbook 中
become: yes和become_user: root是否设置正确。 - Terraform: 检查
user_data脚本中是否包含了正确的sudo命令。
- Ansible: 检查 Playbook 中
- 检查文件/目录权限: 确认脚本要操作的文件或目录的所有者和权限。
- 手动测试权限: 登录到目标服务器,手动执行
配置语法和逻辑错误 (Syntax & Logic Errors)
代码写错了,这是程序员最常遇到的问题。
- 错误表现:
syntax error(语法错误)module not found(模块未找到)undefined variable(变量未定义)- 资源创建失败,提示参数错误。
- 可能原因:
- YAML/Terraform/HCL 语法错误: 缩进错误、冒号后缺少空格、引号不匹配等。
- 变量名拼写错误或未定义。
- 模块或依赖未安装。
- 条件判断或循环逻辑错误。
- 排查思路:
- 使用 Linter 工具:
- YAML: 使用
yamllint检查 Ansible Playbook 的语法。 - Terraform: 运行
terraform fmt来格式化代码并检查缩进,运行terraform validate来验证配置文件的语法。
- YAML: 使用
- 仔细阅读错误信息: 错误信息通常会精确地告诉你哪一行、哪个文件出了问题。
- 检查依赖: 确保所有需要的 Python 库、Ansible 模块、Terraform Provider 都已正确安装。
- 简化问题: 如果一个 Playbook 或 Terraform 配置很复杂,尝试将其拆分成最小的可复现单元,逐步排查是哪一部分的逻辑出了问题。
- 使用 Linter 工具:
状态和幂等性问题 (State & Idempotency Issues)
自动化工具的核心思想是“幂等”,即多次执行同一个任务,结果应该总是一致的,如果不符合,就说明存在状态问题。
- 错误表现:
- Playbook 或
terraform apply每次执行都报错,或者状态不一致。 - 服务启动后立即停止。
- 被意外覆盖。
- Playbook 或
- 可能原因:
- 资源已存在,但脚本尝试以不同方式重新创建它。
- 检查条件写得不对。
stat模块检查文件是否存在,但逻辑判断反了。 - 服务配置有依赖关系,但未按正确顺序处理。
- 排查思路:
- 理解幂等性: 明确你的任务是想“创建”一个资源(如果不存在),还是“确保”一个资源处于某种状态,Ansible 的
state: present和state: started就是为此设计的。 - 使用
--check模式:- Ansible:
ansible-playbook my_playbook.yml --check(只检查不执行) - Terraform:
terraform plan(生成执行计划,可以看到将要发生什么变化)
- Ansible:
- 检查目标服务器的实际状态: 登录到服务器,手动检查文件是否存在、服务是否在运行、软件是否已安装,与期望状态进行对比。
- 理解幂等性: 明确你的任务是想“创建”一个资源(如果不存在),还是“确保”一个资源处于某种状态,Ansible 的
依赖和软件包问题 (Dependency & Package Issues)
自动化脚本安装的软件包版本不正确,或者依赖的库缺失。
- 错误表现:
package xyz is not available(软件包 xyz 不可用)Could not find a version that satisfies the requirement ...(找不到满足要求的版本)- 脚本执行到某一步时,因为缺少某个命令(如
curl,wget)而失败。
- 可能原因:
- 软件包名或版本号错误。
- 目标服务器的软件源配置不正确或已失效。
- 缺少前置依赖。
- 排查思路:
- 手动安装测试: 在目标服务器上,手动运行
apt install <package>或yum install <package>,看是否能成功。 - 检查软件源: 确认
/etc/apt/sources.list或/etc/yum.repos.d/中的源地址是否有效且可访问。 - 使用版本固定: 在自动化脚本中,尽量指定软件包的确切版本号,避免因源中版本更新导致自动化失败。
- 手动安装测试: 在目标服务器上,手动运行
当遇到 "服务器 automation 错误" 时,请遵循以下步骤:
- 保持冷静,不要重复执行。 很多自动化工具(如
terraform apply)在遇到错误后可能会留下不一致的状态,重复执行可能会让问题更糟。 - 收集信息: 复制完整的错误日志和相关的配置代码。
- 分类问题: 根据错误信息,判断它属于连接、权限、语法、状态还是依赖问题。
- 由简到繁排查:
- 先解决最外层的问题(如网络连接)。
- 再解决权限问题。
- 然后深入代码,检查语法和逻辑。
- 最后检查软件包和依赖。
- 善用工具: 充分利用
--check、plan、validate、linter等工具来辅助排查。
如果你能提供更具体的信息,我可以给出更精确的解决方案。